
|
To find statistics and other information that can be used to describe a data set -- which include measures of center (mean, median, mode, midrange), measures related to spread (variance & standard deviation, interquartile range, range), Pearson's Skewness Index, and the identification of outliers ...
R
Presuming data is numeric and has been stored in a vector named data, one can find the mean with
mean(data)and the median with
median(data)There is not a built-in function in R to calculate the midrange, but one can easily write such a function:
midrange = function(v) {
return((max(v) + min(v))/2)
}
A moment should be taken here to point out the (hopefully obvious) nature of the functions used in the above definition:
max(v)returns the maximum element of a vector $v$
min(v)returns the minimum element of a vector $v$
There is also not a built-in function in R to calculate the mode(s) of a data set, but writing one again proves straight-forward (albeit a bit longer). We do, unfortunately, need to name our function something besides mode(), as R does have a function with this name (it has to do with the "storage mode" of an object, as opposed to a measure of center for a data set).
getmode = function(v) {
uniques = unique(v)
counts = tabulate(match(v,uniques))
max.count = max(counts)
return(uniques[counts == max.count])
}
Nicely, the above function works even when the vector is not numeric.
As two examples:
> data = c(1,4,2,6,3,3,4,4,2,5,2)
> getmode(data)
[1] 4 2
> names = c("bob","fred","fred","susan","chuck","alice","chuck")
> getmode(names)
[1] "fred" "chuck"
Let's take a moment and look at what the functions used in the above definition actually do.
unique(v)When $v$ is a vector, this function returns a vector identical to $v$, except with duplicate elements removed.
match(v1,v2)
This function returns a vector of the positions of (first) matches of v1 elements in v2
tabulate(v)
This function counts how many 1's, 2's, 3's, etc., appear in $v$. As an example,
> tabulate(c(2,3,3,5)) [1] 0 1 2 0 1 # <-- i.e., there are 0 ones, 1 two, 2 threes, 0 fours, and 1 five
v = c(1,4,2,6,3,3,4,4,2,5,2)
uniques = unique(v) # <-- uniques = c(1, 4, 2, 6, 3, 5) counts = tabulate(match(v,uniques)) # <-- counts = c(1, 3, 3, 1, 2, 1) max.count = max(counts) # <-- max.count = 3 return(uniques[counts == max.count]) # returns c(4,2)So, not unlike how one finds modes by hand, R first decides which (unique) elements are in the vector $v$ given to it; counts how many of each of these there are in $v$; determines the maximum number of times an element is seen; and then returns those unique values that occur that maximum number of times.
Again presuming the numeric data of interest has been stored in a vector named data, one can calculate the variance, standard deviation, and interquartile range (IQR) with var(data), sd(data), and IQR(data), as shown in the example below:
> data = c(1,2,2,20,4,5,7,3) > var(data) [1] 38 > sd(data) [1] 6.164414 > IQR(data) [1] 3.5
Of course, if one needed the population variance or population standard deviation, one could simply multiply the variance by the appropriate constant. The length() function in R, which returns the number of elements in a vector, and the sqrt() function, which calculates square roots, can both prove useful to this end, as shown in the example:
> data = c(1,2,2,20,4,5,7,3) > n = length(data) # note, here n is 8 > pop.var = var(data) * (n-1) / n > pop.var [1] 33.25 > pop.sd = sqrt(pop.var) > pop.sd [1] 5.766281As for the range of values in a data set, one can of course use the aforementioned
min() and max() functions, or the range() function, as shown below:
> data = c(1,2,2,20,4,5,7,3) > min(data) [1] 1 > max(data) [1] 20 > range(data) [1] 1 20To mention one last way to get a quick feel for the nature of data stored in a given vector, one can also use the
summary() function in R to display all of the following values at once: the minimum, Q1, median, mean, Q3, and maximum values. Below is an example using the built-in rivers dataset:
> rivers [1] 735 320 325 392 524 450 1459 135 465 600 [11] 330 336 280 315 870 906 202 329 290 1000 [21] 600 505 1450 840 1243 890 350 407 286 280 [31] 525 720 390 250 327 230 265 850 210 630 [41] 260 230 360 730 600 306 390 420 291 710 [51] 340 217 281 352 259 250 470 680 570 350 [61] 300 560 900 625 332 2348 1171 3710 2315 2533 [71] 780 280 410 460 260 255 431 350 760 618 [81] 338 981 1306 500 696 605 250 411 1054 735 [91] 233 435 490 310 460 383 375 1270 545 445 [101] 1885 380 300 380 377 425 276 210 800 420 [111] 350 360 538 1100 1205 314 237 610 360 540 [121] 1038 424 310 300 444 301 268 620 215 652 [131] 900 525 246 360 529 500 720 270 430 671 [141] 1770 > summary(rivers) Min. 1st Qu. Median Mean 3rd Qu. Max. 135.0 310.0 425.0 591.2 680.0 3710.0
quantile() function, which gives the cutoff data value under which some percentage of the data lie.
As an example of how this function works, suppose the variable grades gives us scores earned on some test in a statistics class, as shown below:
> grades = c(86,92,100,93,89,95,79,98,68,62,71,75,88,86,93,81,100,86,96,52,15)We can find $Q_1$ with
quantile(grades,0.25), since 25% of the data lies below $Q_1$.
Similarly, quantile(grades,0.75) will give $Q_3$.
Using these, we can quickly identify any outliers with the following:
> lower.bound = quantile(grades,0.25)-1.5*IQR(grades) > upper.bound = quantile(grades,0.75)+1.5*IQR(grades) > c(lower.bound,upper.bound) 25% 75% 48 120
Then, using subsetting, we can identify any specific outliers that might be present:
> grades[grades < lower.bound | grades > upper.bound] [1] 15Thus, $15$ is an outlier as it falls below $Q_1 = 48$.
Of course, another test for outliers involves finding those data values that fall outside of 3 standard deviations from the mean. This is also done in a straight-forward way, as shown in the example below:
> grades = c(86,92,100,93,89,95,79,98,68,62,71,75,88,86,93,81,100,86,96,52,15) > lower.bound = mean(grades) - 3*sd(grades) > upper.bound = mean(grades) + 3*sd(grades) > c(lower.bound,upper.bound) [1] 21.58463 140.79632 > grades[grades < lower.bound | grades > upper.bound] [1] 15
The following function can be used to calculate Pearson's Skewness Index for a given data set:
pearson.skew = function(v) {
return(3*(mean(v)-median(v))/sd(v))
}
Excel:
The most important functions in Excel, when it comes to describing data, are:
The following worksheet illustrates how these functions can be used to calculate measures of center (mean, median, mode, midrange), measures of spread (standard deviation, interquartile range, range), Pearson's Skewness Index, and the "fences" used in determining if a value represents an outlier in accordance with both the means test and IQR test:
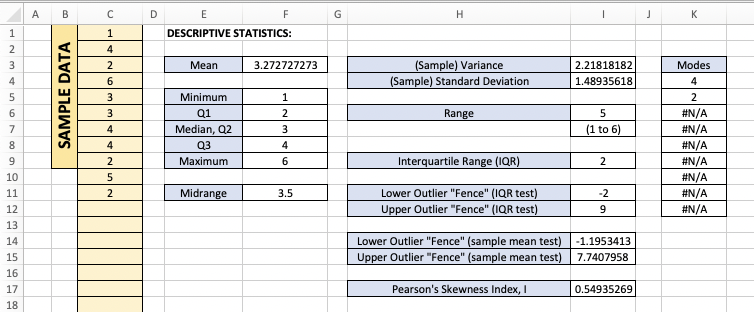
Here are the relevant formulas for the cells in column F:
F3:"=AVERAGE(C:C)" # calculates the mean of all values in column C
F5:"=MIN(C:C)" # calculates the minimum value in column C
F6:"=QUARTILE.INC(C:C,1)" # calculates Q1 for the data in column C.
# note: Excel includes a QUARTILE.EXC function
# as well, although both of these may differ
# slightly from hand calculations of Q1 and Q3
F7:"=MEDIAN(C:C)" # calculates the median of all values in column C
F8:"=QUARTILE.INC(C:C,3)" # calculates Q3 for the data in column C.
# similar to F6 above
F9:"=MAX(C:C)" # calculates the maximum value in column C
And here are the formulas for cells in column I:
I3:"=VAR.S(C:C)" # calculates the sample variance of column C values
# note: if column C had represented a population
# instead, one should use the VAR.P() function
# for the population variance
I4:"=STDEV.S(C:C)" # calculates the sample standard deviation of
# column C values. if this column had represented
# a population instead of a sample, one should use
# STDEV.P(C:C) instead for the population standard
# deviation
I6:"=F9-F5" # the range of the data (i.e, max - min)
I7:"=CONCATENATE("(",F5," to ",F9,")")" # builds a string of text from the
# smaller strings and/or values given
# to it
I9:"=F8-F6" # the IQR of the data (i.e., Q3 - Q1)
I11:"=F5-1.5*I9" # the lower outlier fence, in accordance with the IQR
# cut-off of Q1 - 1.5*IQR
I12:"=F9+1.5*I9" # the upper outlier fence, in accordance with the IQR
# cut-off of Q3 + 1.5*IQR
I14:"=F3-3*I4" # the lower outlier fence, in accordance with the
# sample mean outlier test cut-off of x.bar - 3*s
I15:"=F3+3*I4" # the upper outlier fence, in accordance with the
# sample mean outlier test cut-off of x.bar + 3*s
I17:"=3*(F3-F7)/I4" # Pearson's skewness index: 3*(mean-median)/standard dev.
Finally, column $K$ shows the modes of the data (remember, there can be more than one).
The way some versions of Excel handle modes can be a bit clunky. As of September 2018, a better way is being investigated -- but until then, here's how you can replicate the above..
First, make a conservative guess for the number of modes your data might have (i.e., guess higher than you think it should be), and then highlight this many cells in a column. In the worksheet above, I allowed for up to 9 modes, selecting $K4:K12$.
Then, while all of these cells are selected, click in the Formula Bar. You are now in a position to type an "array formula". Type "=MODE.MULT(C:C)", and then to signify this should be treated as an array formula, hit Ctrl-Shift-Enter. The result is to display all of the modes in the cells you selected. If the number of cells selected is too small, some modes are not shown. If the number of cells is too big, you will see some "#N/A" error values. Like I said -- clunky.