
|
A tacit assumption of binary search trees, 2-3 trees, and red black trees is that the keys they employ are comparable -- that is to say they have some total order associated with them, that lets us navigate the links of the tree for retrieval, insertion, etc. by making comparisons between keys.
What should one do if the keys a client must employ in a symbol table aren't comparable? ..if they don't have such an order associated with them?
The quick answer, of course, is to give them an order!
One straight-forward way to do this would be to find some function $h(k)$ that we can apply to a key $k$ to produce some non-negative integer. Non-negative integers certainly have a total order associated with them. Of course, one must be careful that the output of the function for two different keys is not the same -- which might be difficult to do, depending on the nature of the key.
Presuming this difficulty can be overcome, we could then use these integers as substitute keys in one of our tree-based symbol tables.
But wait!
If we have tied each key to a non-negative integer -- couldn't we bypass all the tree-based stuff, and just put our value in an array at whatever position our integer suggests?
If we did, retrieval of values associated with keys would be almost immediate! Suppose the array is named $a$. To get the value for some key $k$, we simply access $a[h(k)]$ -- and we are done! To insert a value for key $k$, we simply assign this value to this same array position -- and we are done! If this can be made to work, we'll have constant running time for retrieval and insertions! Why have we spent so much time developing binary search trees, 2-3 trees, and red-black trees, you ask -- when we could have done this all along?
We must be careful not to get too excited, as there are still plenty of potential problems -- problems that can potentially slow the process of value retrieval/insertion all the way back down to $O(n)$, or require mammoth amounts of memory -- making the tree-based options better in some situations. However, the promise this approach affords is substantial and forms the basic idea behind hash tables.
As some verbiage that will make the discussion below easier to read, we refer to the function $h(k)$ that maps keys $k$ to their respective array indices, as a hash function. We also say a key $k$ hashes to slot $h(k)$ in the hash table, and that $h(k)$ is the hash code (or sometimes simply the hash) for key $k$.
Consider the case where one's keys are strings of text. Perhaps they represent transaction codes used by some business, known to be no more than 10 characters long.
If every possible transaction code must be mapped by some function $f(x)$ to a different array index, how big of an array will we need? Even limiting things to alpha-numeric characters, we have $36^{10} = 3,656,158,440,062,976$ different possible codes. As such, we would need an array this same size! For comparison, if a transaction happened every second for 10 years, we would only amass $315,360,000$ total transactions, filling only $0.000008\%$ of our array. That's a lot of wasted space! Indeed, even if the values to be stored were individual 8-bit ascii characters -- we are talking about roughly 457 terabytes of memory going unused.
Clearly the above is unacceptable. However, if we use a smaller array we necessarily create the possibility that different keys could get hashed to the same slot by our hash function. For the mathematically inclined, this is an immediate result of the pigeon-hole principle.
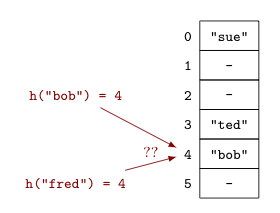
When collisions occur, like when we try to insert "fred" into the hash table at right in the slot already occupied by the previous insertion of "bob", we need to find some other place to put our value -- one that can be quickly found in the future. There are a couple of options for how to resolve collisions (e.g., separate chaining and linear probing), but both come at the cost of additional time for the insertion and retrieval processes.
The smaller the array we use, the more collisions we are likely to have. In this way, what we save in space, we lose in execution time -- and vice-versa. The good news is this trade-off between time and space associated with hash tables can be "dialed back and forth" to whatever is acceptable for the context at hand.
Even disregarding the necessary possibility of collisions arising from the array's length being shorter than the number of possible keys, we can get additional collisions from poorly designed hash functions, whose outputs are not uniformly distributed (i.e., all equally likely).
Suppose the keys for a given context are phone numbers, and we had decided to use an array of length 1000. Noticing that the indices range from $0$ to $999$, we will need to hash our 10-digit phone numbers down to 3-digit indices. One way to do this would be to use the first three digits of the number (i.e., the area code) -- but this would be a bad decision! Think of all of the people in your local area that share the same area code as you -- any two of your numbers added to the array would create a collision!
Using the last three digits would be a much better choice, as these triples are likely to be more uniformly distributed.
| Letter | Relative frequency as the first letter of an English word | |
|---|---|---|
| a | 11.682% | |
| b | 4.434% | |
| c | 5.238% | |
| d | 3.174% | |
| e | 2.799% | |
| f | 4.027% | |
| g | 1.642% | |
| h | 4.200% | |
| i | 7.294% | |
| j | 0.511% | |
| k | 0.856% | |
| l | 2.415% | |
| m | 3.826% | |
| n | 2.284% | |
| o | 7.631% | |
| p | 4.319% | |
| q | 0.222% | |
| r | 2.826% | |
| s | 6.686% | |
| t | 15.978% | |
| u | 1.183% | |
| v | 0.824% | |
| w | 5.497% | |
| x | 0.045% | |
| y | 0.763% | |
| z | 0.045% | |
Similarly, if the keys are English words, making the hash function output depend solely on the first letter of these words is a bad idea as well. To see this, note that some letters are more likely to be first letters than others, as can be seen in the table at right.
The chances that the first letter of a word is $T$, for example, is around 16% -- more than 4 times larger than it would be if letters were uniformly distributed. Just looking at the insertion of two such keys, the chances of seeing a collision is about 7.35%, whereas if first letters of words were randomly and uniformly distributed -- the chances of a collision drops to about 3.8%.
The moral of the story is that the distribution of the outputs of our hash function matters a great deal -- and the closer we can get this distribution to be uniform, the better of a job we will do in reducing collisions.
Of course, from a practical standpoint, given the great variety of distributions that might be related to the keys one wishes to use, it appears we will potentially need a different approach for hashing every different class of key we might have.
The good news is that Java's Object class, whose methods are inherited by every class, includes a method hashCode() just for this purpose!