
|
A binary search tree (BST) provides a way to implement a symbol table that combines the flexibility of insertion in linked lists with the efficiency of searching in an ordered array. BSTs are a dynamic data structure that is fast to both search and insert.
Recall how linked lists are built from nodes that each contain a reference to some other node. A binary search tree is similarly constructed -- except that each node now contains a key value, some associated data, and two references to other nodes. We often refer to these two node references as the left node and the right node, as the picture below suggests.
In this picture, each node is represented by a circle, with the value of the corresponding key shown inside. The data associated with each node might be significant in size and is not terribly relevant to the structure of the tree. Thus -- unless there is a need for doing so -- we generally opt not to show the node data in these tree diagrams to keep things simple. The arrows to the left and right of each circle represent the corresponding references to the left and right nodes, as suggested by their direction.
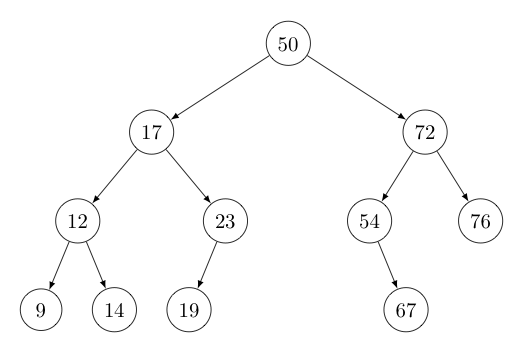
Note, we often omit the arrow-tips to keep the drawings simpler. Also, when one of the arrows/segments is missing (or replaced by a short segment that doesn't terminate in a node), we assume the corresponding reference is null.
The words we use to describe trees in computer science employs a strange mixture of imagery...
If a node A references nodes B and C, then B and C are called A's children. In a binary tree, there are two children (possibly null) for any one node. One of these is referred to as the left child, while the other is the right child. Naturally, if nodes B and C are children of node A, then node A is referred to as the parent of nodes B and C. Note, every node in a tree, with the exception of the top-most node, has one and only one parent.
Switching metaphors, nodes without children (i.e., both references they contain are null) are called leaves, while the top-most node of the tree is called the root. Note, for any given tree there is only one root. Curiously, binary trees are always drawn upside from their wooden counter-parts in nature -- with their leaves at the "bottom" and the root at the "top".
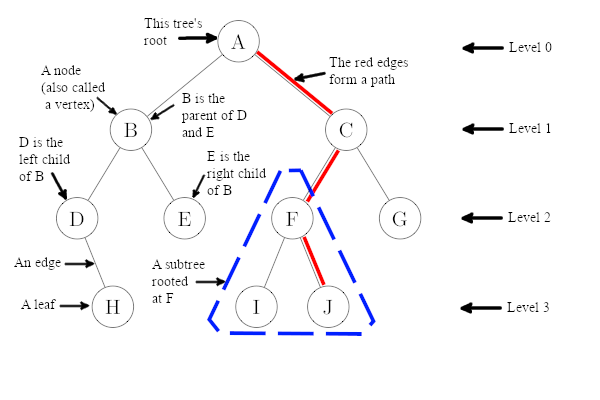
We describe a node taken together with all of its descendants (i.e., its children, its children's children, etc.) as a subtree. Importantly, a subtree rooted at anything but the original tree's root will always be smaller (in terms of numbers of nodes) than the original tree. As such, many operations on trees can be implemented in a recursive way, where the recursive call is applied to a subtree of the original tree.
Now re-envisioning the tree as a network of roads, we refer to checking the value of a node as visiting that node, and describe the sequence of nodes that must be visited as one travels from the root to a given node, as the path to that node. Note, each such path in a tree is unique.
Each segment (or arrow) drawn from one node to another is called an edge. The origin of this term is related to the edges of a platonic solid, like a cube - think about tracing your finger along the edge of a cube until you come to a corner, where things split into two other edges. In this case, the corner plays the role of a node, which is also called a vertex. Granted, the network of edges and vertices associated with a cube -- when drawn on paper -- doesn't look like a tree. However, such networks are examples of a more general type of data structure called a graph. A tree is one type of graph; there are many others. We will look at graphs in much greater detail later...
If every node's key is both larger than all keys in its left subtree and smaller than all keys in its right subtree, we say the tree is in symmetric order. As an example, the tree on the left below is in symmetric order, while the one on the right is not. As we will soon see, having a tree's nodes in symmetric order by key greatly facilitates searching for (and inserting) a node with a given key.
| Symmetric Order | Not Symmetric Order |
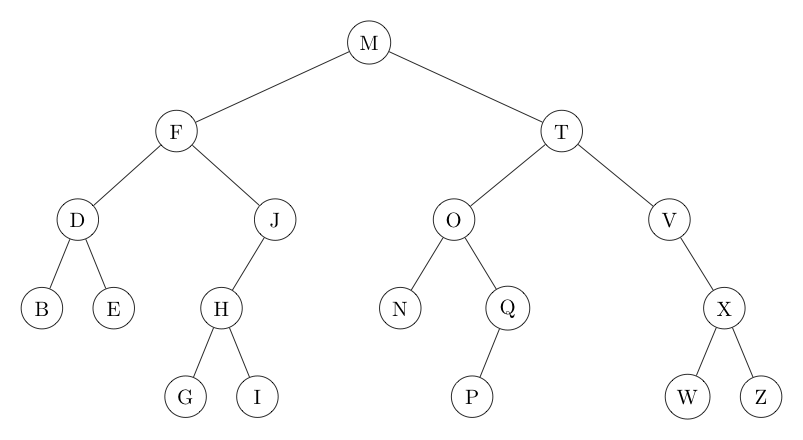 |
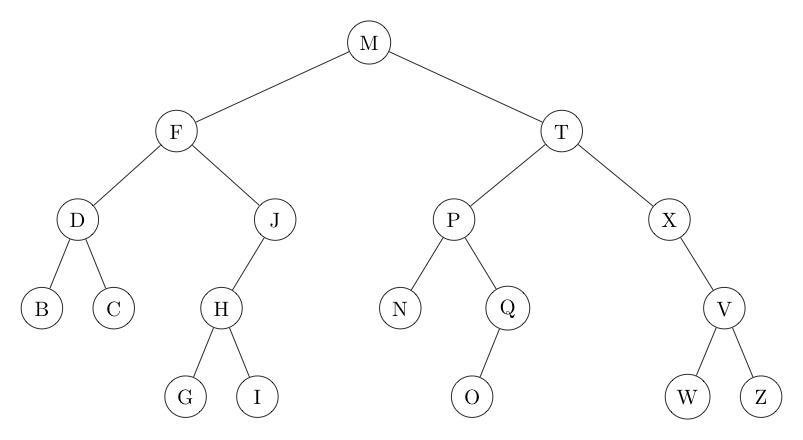
|
The level (or depth) of a particular node is the length (counted in edges) of the aforementioned unique path to that node from the root. This of course makes the root at level 0. The notion of level is very important when it comes to finding cost functions for the various operations we need to do with trees. For example, in searching for a key in a binary search tree, one starts at the root and navigates down the unique path to the node with the key in question, choosing to "go left" or "go right" as one descends the tree as the key value sought and symmetric order dictate. Thus, in finding this path, one comparison is made for each node on the path, making the total number of comparisons equal to exactly one more than the level of the node sought. The maximum level in a tree is called its height. The height of a tree corresponds to the "worst case" in terms of how many comparisons must be made in a binary search tree before finding a node with a particular key.
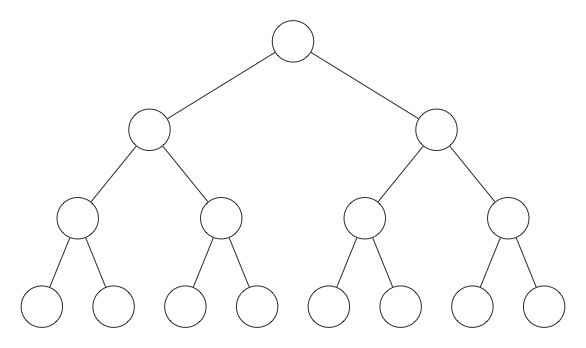
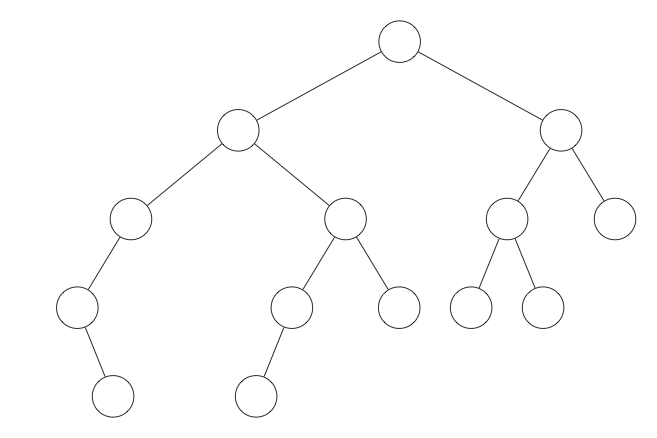
The size of a tree refers to the number of nodes it contains. Clearly, the height of the "average" tree of size $n$ goes up as $n$ increases. However, we can keep this height to a minimum if we keep the tree perfectly balanced. To be precise, we say a binary tree is considered to be perfectly balanced if every non-leaf node has both a left and right child and every leaf node is at the same level. Examples of a perfectly balanced tree and a tree that is not perfectly balanced are shown below:
| Perfectly Balanced | Not Perfectly Balanced |
|
|
For a reasonably balanced tree of $n$ nodes, the height is $O(\ln n)$. To see this, note that in a perfectly balanced tree of height $m$, we have $1$ node of level $0$; $2$ nodes of level $1$; $4$ nodes of level $2$, etc. This means we have a total number of nodes equal to $$n = 2^0 + 2^1 + 2^2 + 2^3 + \cdots + 2^m = 2^{m+1} - 1$$ The last equality is the result of the standard formula for the value of a geometric series of $n$ terms, with first term $1$ and common ratio (between consecutive terms) of $r$, $$\sum_{i=0}^{n} r^i = \frac{r^{n+1} - 1}{r-1}$$ In our case, note the common ratio between consecutive terms is $r=2$.
Solving the resulting equation $n = 2^{m+1} - 1$ for $m$, we find $m = \log_2 (n+1) - 1$, which is $O(\ln n)$ as claimed.